


패스트캠퍼스 Python 코딩테스트 강의 [개발자 취업 합격 패스 with 코딩테스트, 기술면접]를 수강하며 정리한 글입니다🤓
Content
이번에는 앞서 배운 내용들을 바탕으로 고급 정렬 알고리즘을 배웠다
퀵 정렬
정렬 알고리즘의 꽃이라고도 불림.
강사도 퀵 정렬을 보고 나서, 알고리즘을 효과적으로 작성할 수 있다는 것을 생각하였다고 함
python으로 특히 코드가 아름다움
기준점 pivot을 정하여 기준보다 작은 것을 왼쪽, 큰 것을 오른쪽으로 모으는 함수
왼쪽과 오른쪽은 각각 재귀용법을 사용하여 다시 동일함수 호출하며 반복함.
함수에서는 왼쪽+기준점+오른쪽을 리턴
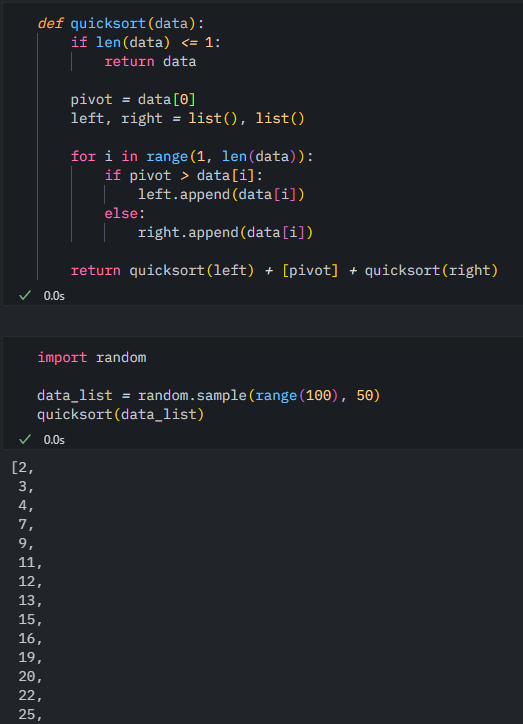
퀵 정렬을 위와 같이 일반적으로 구현해 보았다.
이를 Python의 list comprehension을 사용하여 더 깔끔하게 구현해 보면,
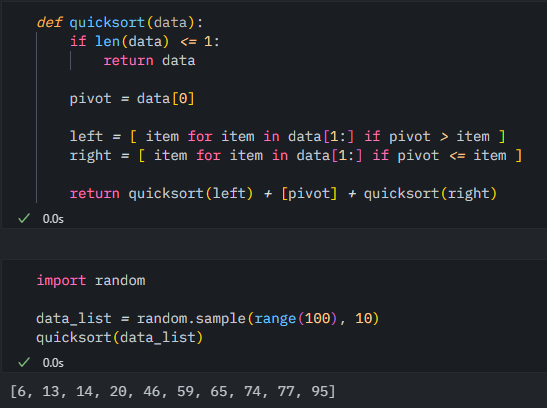
이렇게 더 python 답게 구현 가능🤓
시간 복잡도는 일반적으로 O(nlogn)이며,
최악의 경우 (가장 작거나 큰 수가 pivot이 되어 한쪽 방향으로만 정렬하여 단계가 총 N 단계가 나오는 경우)
O(n^2) 의 시간 복잡도를 가질 수 있다.
병합 정렬
재귀 용법을 활용한 정렬 알고리즘
분리하는 로직(split), 합치는 로직(merge)으로 구성됨
아래와 같이 분리하는 함수 mergesplit() 후 합치는 함수 merge() 가 실행되게 함
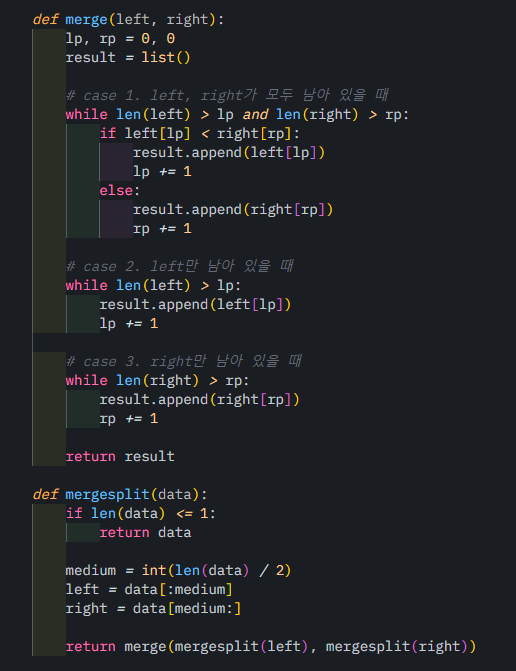
mergesplit 함수 안에 mergesplit 함수를 호출하는 재귀용법을 사용하여 길이가 1인 아주 작은 상태로 쪼갠 후
merge 해 나가도록 구현했다
분할 정복 알고리즘의 대표적인 예이다. 아주 작게 쪼갠 후 해결해 나가는..
분할 정복 알고리즘은 재귀용법을 잘 사용하곤 함
시간 복잡도는... 너무 복잡한데...
O(nlogn)정도..
이진 탐색
데이터가 들어 있을 때 데이터를 빠르게 탐색하는 방법은 앞서 데이터 구조에서도 많이 배웠다
순차 탐색, 해시 구조, 이진 탐색 트리, ...
분할 정복 알고리즘과 이진 탐색?
- 분할 정복 알고리즘
Divide-문제를 하나 또는 둘 이상으로 나눈다
Conquer-나눠진 문제가 충분히 작고 해결 가능하다면 해결하고, 아니면 다시 나눈다
- 이진 탐색
Divide-리스트를 두 개의 서브 리스트로 나눈다
Conquer-검색할 숫자와 중간값을 비교하여 뒷부분 또는 앞부분 서브 리스트에서 검색할 숫자를 찾는다
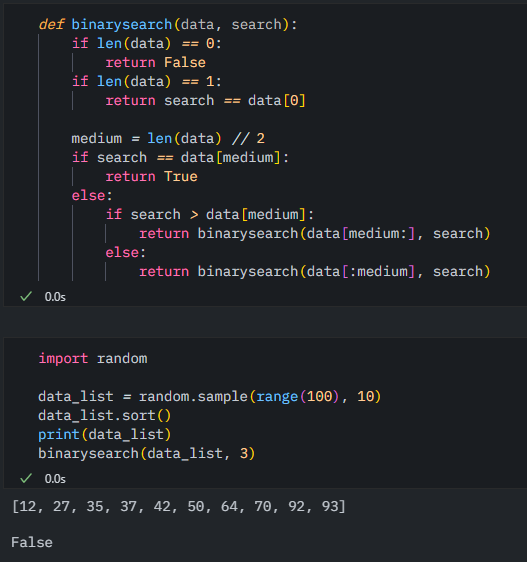
자알 구현되었습니다
시간 복잡도는 O(nlogn) 입니다
순차 탐색
쉬어가는 순차 탐색~,~
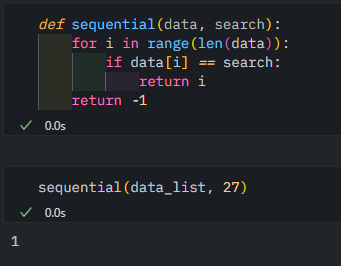
최악의 경우에는 리스트 길이 n일 때 n번 비교해야 함.
시간 복잡도는 O(n)
그래프
사물, 데이터를 정점(Vertex) 또는 노드(Node)라고 부르며, 간선(Edge)로 이어 표현한다
간선에 방향이 없는 무방향 그래프, 방향이 있는 방향 그래프
간선에 비용 또는 가중치가 있는 가중치 그래프 또는 네트워크
시작 노드와 종료 노드가 동일한 사이클 그래프, 사이클이 없는 비순환 그래프
모든 노드가 서로 연결되어 있는 완전 그래프
그래프와 트리 차이?
트리는 그래프의 한 종류로, 방향성이 있는 비순환 그래프.
방향성이 없고, 사이클이 존재하지 않으며. 루트노드가 존재함. 부모자식 개념 존재
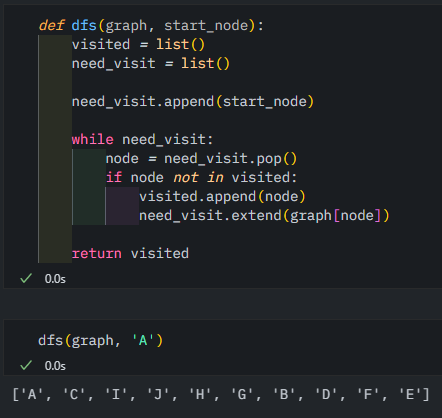
너비 우선 탐색 BFS
같은 레벨에 있는 노드를 먼저 탐색하는 방법
visited와 need_visited 라는 Queue를 가지고 순회를 한다
python에서 queue를 사용할 때 import해서 사용할 수도 있지만, list()를 사용하며 pop(0)처럼 이용하면 queue와 같이 사용할 수 있음

BFS 방법으로 잘 탐색되도록 구현된 것을 확인할 수 있따
위 코드의 시간 복잡도는, 노드 수: V, 간선 수: E 일 때
O(V+E)이다.
while문에서 V+E만큼 수행하기 때문
깊이 우선 탐색 DFS
정점의 자식들을 먼저 탐색하는 방법

탐욕 알고리즘
최적의 해에 가까운 값을 구하기 위해 사용됨
여러 경우 중 하나를 결정해야 할 때마다 최적이라고 생각되는 경우를 선택하는 방식..
알고리즘이라기보다는 전략이라고 생각하면 쉬울 듯
대표적인 Greedy Algorithm 활용의 예는 아래와 같다
1. 동전 문제
지불해야 하는 값이 N원일 때, 동전 A B C D으로 동전 수가 가장 적게 지불하시오
➡️ 가장 큰 동전부터 최대한 지불해야 하는 값을 채우도록 구현
➡️ 탐욕 알고리즘으로 매 순간 최적이라고 생각되는 경우 선택

2. 부분 배낭 문제 Fractional Knapsack Problem
무게 제한이 K인 배낭에 최대 가치를 가지도록 물건 넣으시오
➡️ 가치/무게를 계산하여 높은 것부터 최대한 채우도록 구현
➡️ 포인트는 지금 순간의 가장 최적의 것부터 하기 위해 Sorting 하여 처리하는 것! 전체 후보들을 고려하지 않음.
물건을 쪼갤 수 있는 부분 배낭 문제 말고도, 쪼갤 수 없는 0/1 Knapsack Problem이 있음.

하지만~~~
탐욕 알고리즘에는 한계가 있따
반드시 최적의 해를 구할 수 있는 것은 아니기 때문에 근사치 추정에만 활용함.
최적의 해에 가까운 값을 구하는 방법 중 하나
탐욕 알고리즘도 코딩테스트에서 자주 나오는 주요 알고리즘인데,
탐욕 알고리즘은 자주 나오는 패턴이 있어 여러 개 풀다 보면 코드 작성의 패턴이 보이게 될 것이다
다른 알고리즘보다 좀 더 쉽게 내 것으로 만들 수 있을 것
위에서 다룬 2 문제와 같이, 우선 sorting을 먼저 한 후 데이터에 대한 처리를 하는 방식으로 보통 구성된다
최단 경로 알고리즘
일상생활의 문제를 해결하는 데에도 잘 사용되는 알고리즘.
난이도는 최상이다. 누구에게나 어렵다는 점을 인지하고 수강하면 좋겠다.
문제 종류
1. 단일 출발 및 단일 도착
2. 단일 출발 최단 경로
: 특정 노드와 모든 노드 간의 최단 경로
3. 전체 쌍 최단 경로
: 전체 노드들 간의 최단 경로
다익스트라 알고리즘
각각 노드들과 특정 출발점 간의 최단 거리를 구하는 알고리즘
우선순위 큐를 활용한 다익스트라 알고리즘
첫 정점에서 해당 노드로 가는 거리가 더 짧을 경우 배열에 해당 노드의 거리를 업데이트
업데이트된 경우 우선순위 큐에 다시 넣음
BFS과 유사하게 첫 정점에 인접한 노드를 순차적으로 방문하게 됨
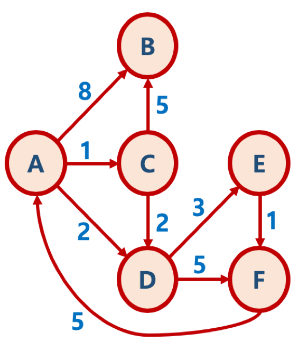
A에서 시작하는 위와 같은 그래프에서
heapq 라이브러리로 우선순위 큐를 사용하여 Dijkstra Algorithm을 구현하면 아래와 같다

이 알고리즘 시간 복잡도를 계산해보장
우선 여기에는 크게 두 가지의 과정이 있다.
1. 각 노드마다 인접한 간선을 모두 검사하는 과정
2. 우선순위 큐에 노드/거리 정보를 push 하고 pop 하는 과정
과정 1의 경우,
O(E) 시간 복잡도가 소요된다. (E: edge, 간선)
과정 2의 경우,
최악의 시간을 가정해 보면, '간선을 체크할 때마다 배열에 들어가 있는 최단 거리 값보다 더 작은 시간이 되어서, 검사할 때 마다 우선순위 큐에 넣는 경우'이다.
최대 O(E) 시간마다 우선순위 큐에 데이터를 넣으면, 최소 heap을 유지하는 시간(최소 값이 제일 위로 올라와 트리를 유지하는 시간) O(ElogE)가 걸린다.
그래서 총 시간 복잡도는 O(E) + O(ElogE) = O(ElogE) 이다.
최소 신장 트리
Spanning Tree 또는 신장 트리라고 부름
그래프의 모든 노드가 연결되어 있으면서 트리 속성을 만족하는 그래프
신장 트리란, 그래프의 모든 노드를 포함, 모든 노드가 서로 연결, 트리 속성 만족(사이클 존재하지 않음)
최소 신장 트리란, 가능한 Spanning Tree 중에서 간선의 가중치 합이 최소인 트리
일상생활에서도 많이 쓰임. 이를테면 네비게이션
난이도가 상당히 높아 다른 강의, 서적에서 다루지 않는(가볍게 다루고 넘어가는) 경우가 많다
크루스칼 알고리즘
탐욕 알고리즘과 비슷하게, 가장 낮은 간선을 선택하는 방식
방법
1. 모든 정점을 독립적인 집합으로 만든다
2. 모든 간선을 비용 기준으로 정렬, 비용이 작은 간선부터 양 끝의 두 정점을 비교
3. 두 정점의 최상위 정점 확인, 서로 다를 경우 연결 (사이클이 생기지 않으면 연결)
위 방법을 보면 간단해 보이지만,
사이클이 생기는지 확인하는 3번 과정이 꽤 복잡하다
이에 사용하는 Union-Find 알고리즘을 먼저 구현해보좌
Union-Find 알고리즘
크루스칼 알고리즘에만 사용되는 알고리즘은 아니고, Disjoint Set 표현할 때에 사용되는 알고리즘이다
Disjoint Set: 서로 중복되지 않는 부분 집합들로 이루어진 원소에 대한 자료 구조
크게 3가지 과정으로 이루어짐
1. 초기화: 각 노드를 독립된 집합으로 나누는 것
2. Union: 간선을 연결하는 작업. 2 집합을 하나로 연결하는 과정
3. Find: 사이클을 체크하는 과정. 두 노드를 연결할 때 각 root 노드를 체크하여 동일하다면 이미 연결되어있는 부분 집합에 들어가 있군, 사이클이 생기겠군, 하고 넘김
마치 링크드 리스트의 제일 root를 찾기위해 쭉 올라가는 시간복잡도를 가지게 됨 → 최악의 경우 O(n)
이런 문제를 해결하기 위해 union-by-rank, path compression 기법을 사용
- union-by-rank 기법
두 부분집합을 합할 때 높이를 작게 하기 위한 기법
두 트리 중 높은 트리의 root에 연결하여 rank가 적게 함
- path compression
Find를 실행한 노드에서 루트에 다이렉트로 연결하는 방법.
Find를 실행한 노드는 다음부터는 루트 노드를 한 번에 알 수 있게 됨
이 두 방법으로 시간복잡도를 크게 낮출 수 있다고 함😵💫
Link
https://fastcampus.co.kr/dev_online_devjob
개발자 취업 합격 패스 With 코딩테스트, 기술면접 초격차 패키지 Online. | 패스트캠퍼스
전문가의 코딩테스트 풀이 강의, 기술면접 합격 수준 답안 강의, 네카라쿠배 합격자의 극비 노하우까지 빠짐없이 담았습니다.
fastcampus.co.kr
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
#패스트캠퍼스 #패캠 #FASTCAMPUS #자바 #자바스크립트 #파이썬 #코딩테스트 #패스트캠퍼스후기 #코딩교육 #코딩자격증
'ProblemSolving' 카테고리의 다른 글
| Kruskal's Algorithm with Python (0) | 2023.06.23 |
|---|---|
| 패스트캠퍼스 Python 코딩테스트 강의 한 달 후기 (0) | 2023.05.17 |
| 패스트캠퍼스 Python 코딩테스트 강의 3주차 (0) | 2023.05.07 |
| 패스트캠퍼스 Python 코딩테스트 강의 2주차 (0) | 2023.04.30 |
| 패스트캠퍼스 Python 코딩테스트 강의 1주차 (0) | 2023.04.23 |