

Object Detection 프로그램을 구현하며 학습한 내용들을 정리하고자 글을 작성합니다.
이번에 처음 접해본 기술이었기 때문에 정보/용어/방법에 오류가 있을 수 있음을 미리 알립니다!
Object Detection이란

가장 먼저, 이미지 속 single object를 감지하는 Object Classification이 있습니다. output으로는 object가 어떤 물체인지에 대한 class와 probability가 있으며 object의 위치는 알 수 없습니다.
이후 single object의 위치까지 감지할 수 있는 Object Localization이 나옵니다. 하나의 객체에 대한 class, probablity, 물체의 위치를 나타내는 bounding box(x, y, w, h)를 output으로 반환합니다.
더 나아가 multiple object의 종류와 위치를 감지하는 Object Detection이 있습니다. 하나의 이미지에서 여러 개의 물체를 파악할 수 있으며, 이 또한 class, probablity, bounding box를 반환합니다.
Object Detection을 하기 위해서는 두 단계의 작업이 필요합니다.
1. Object Localization
2. Object Classification
Object Localization
Object Localization은 이미지 안에서 물체가 어느 위치에 있는지 파악하는 과정을 말합니다. (localize: ...의 위치를 알아내다.)
객체가 존재할 만한, 관심있는 위치 RoI(Region of Interest)를 파악합니다. 이를 통해 추론된 위치는 Bounding box*로 표현됩니다. (bounding box: 객체의 좌표를 표시하기 위한 박스 형태)
Object Localization의 방법에는 두 가지가 있습니다.
방법 1. Sliding Window
이미지 내에서 다양한 형태의 window를 슬라이딩해가며 물체가 존재하는지 확인하는 방법입니다. 너무 많은 영역에 다양한 크기의 window로 확인해야 한다는 단점이 있습니다.
방법 2. Selective Search
인접한 영역끼리의 유사성을 측정하여 큰 영역으로 통합해 나가는 방식입니다.
뒤에서 가볍게 다루어볼 R-CNN, Fast R-CNN 알고리즘에서 사용되는 방식이며 CPU에서 수행됩니다.
Object Classification
이미지 내의 객체 종류(Class)가 무엇인지 구분하는 과정입니다.
Traditional Image Processing
HoG
Histogram of Gradient
이미지 내의 픽셀들의 크기와 방향 변화를 나타내는 Gradient에 대한 Histogram을 사용하는 방식입니다.
하나의 픽셀에는 위의 그림과 같이 크기와 방향이 나타나는 Gradient*가 계산되고, 이를 통해 Feature point를 찾은 후 물체를 인식합니다.
Gradient란, 이미지 안의 수많은 픽셀들의 인접한 픽셀 간의 대비, 밝기 값 차이가 얼마나 큰가에 대한 수치를 말합니다.
이미지의 픽셀들은 z=f(x,y) 형태의 밝기 값으로 표현되는데, 이것으로 gradient의 크기와 방향 성분이 계산됩니다.
물체의 중심부와 테두리가 있을 때, Gradient 값이 큰 부분은 테두리이기 때문에 이를 통해 물체의 위치를 파악합니다.
DPM
Deformable Part Model

이 방법의 동작 순서는 아래와 같습니다.
1. Sliding window 방식으로 이미지를 여러 개로 나눈다.
2. 각 Bounding box의 block 마다 HoG를 분석하여 해당 block의 특징을 선별한다.
3. 수집된 feature를 토대로 Classification 작업을 수행한다.
Classification을 수행할 때에는 미리 수집된 template filter를 사용합니다.
사람을 예로 들었을 때, 얼굴, 팔, 다리 등의 특성이 담긴 template filter를 미리 수집한 후, bounding box 영역마다 SVM*을 통해 Classification 합니다.
SVM(Support Vector Machine)이란 인공지능 기계학습 분야 중 하나로, 패턴 인식, 자료 분석을 위한 지도학습 모델입니다. 2개의 범주를 구분하는 이진 범주기로, 데이터가 어느 카테고리에 속하는지 판단합니다.
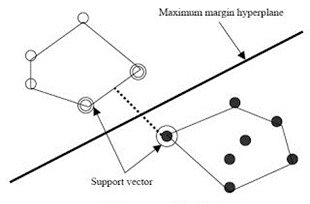

이 방법의 문제점은 Sliding window 방식으로 만들어진 수많은 bounding box에 모두 복잡한 classification 과정을 수행해야 한다는 점입니다. 이 때문에 느린 속도가 단점입니다.
ML based Algorithm - Two stage 방식
Localization을 수행한 후, Classification을 순차적으로 수행하여 결과를 얻어 Two-stage 방식으로 불립니다.
후보 object 위치를 제안한 후, 어떤 종류의 객체인지 Class를 예측합니다.

이 방식은 비교적 정확도가 높다는 장점이 있지만, Region proposal을 추출하는 데에 오랜 시간이 걸리고, Classification에 오랜 시간이 걸리며, training과 testing에 많은 시간이 필요하다는 단점이 있습니다. 이 때문에 실시간 서비스에는 적용하기 어렵다는 문제점이 있습니다.
ML based Algorithm - One stage 방식
기존에 발표되었던 DPM의 Sliding window, R-CNN의 Selective search와 같은 방식은 물체의 위치를 파악하는 Localization의 속도 문제가 있었습니다.

느린 속도를 개선하기 위해 Grid 개념을 도입하여 속도를 향상시켰습니다. 단, 2-stage 방식에 비해 정확도가 떨어진다는 단점이 있습니다.
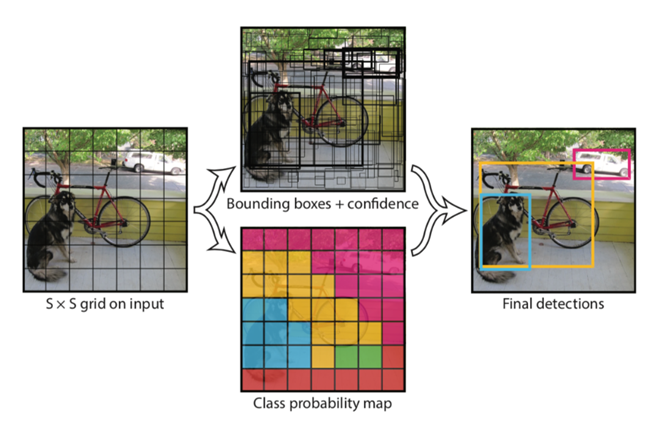
특징은 Unified* Detection이라는 점입니다. (unified: 통합된)
기존에는 Localization과 Classification을 따로 진행하던 것을 한 번에 하는 방식입니다.
input image를 SxS의 grid로 나누어 각 grid cell에서 B개의 bounding box(bbox)를 예측하고, 해당 bbox에 대한 Confidence Score를 예측합니다. (Confidence score: 해당 bbox 안에 물체가 있는지 없는지 확률로 나타낸 값, 신뢰도)
Inference가 굉장히 빠르다는 점, 전체 이미지를 보고 Object detection을 수행하기 때문에 배경 오류가 적고 일반화 성능이 좋다는 장점이 있습니다.
단점으로는, grid cell이 하나의 클래스만 예측하기 때문에 하나의 cell에 작은 object가 여러 개 있다면 예측이 어렵습니다. 또한 Bounding box 예측 시에 bbox regression을 하지 않고 바로 bbox를 예측하기 때문에 bbox를 찾는 성능이 떨어집니다. 이로 인해 비교적 낮은 정확도를 제공합니다.
저는 이 세 가지 방법 중 one-stage 방식의 YOLOv5 알고리즘을 사용하여 실시간 물체 인식 서비스를 구현했습니다🥹
Custom dataset을 학습시키고, 모델을 사용하여 서비스를 구현한 과정도 글로 정리해 보겠습니다.
수정이 필요한 부분이 있다면 알려주세요. 감사합니다!